AWS personalize를 통한 개인화 추천
이번 포스트에서는 퍼블릭 클라우드를 활용한 추천 엔진 구축에 대해 알아보겠습니다.
현재 퍼블릭 클라우드로 추천 시스템을 구축할 수 있는 방법은 다음과 같습니다.
-
AWS Personalize
-
GCP Recommendation
-
Azure Recommendation
이번에 다룰 SaaS 서비스는 AWS Personalize로 제 생각에는 클라우드 3사 중 가장 성능이 좋고, 각종 소스가 많아 구축하기 용이하다고 생각됩니다. 현재 저희 회사에서 해당 솔루션을 가지고 상용화를 진행했는데 공유드리기에 적합하다 생각되어 포스트를 남기게 되었습니다.
이제 Personalize를 통해 추천 실제 엔진을 구축해보겠습니다. 클라우드를 사용하기 위해선 먼저 계정 생성을 해주셔야 합니다. 이전에는 계정 생성 시 무료 크레딧을 줬는데 지금은 주는지 확실하게 모르겠네요. 클라우드의 장점은 아시죠? 사용하는 만큼 돈을 낸다는 거! 자세한 전체 방법은 아래 링크에 있으니 해당 document를 참고하시면서 따라해보세요. 혹시라도 문제가 생기거나 궁금한 내용은 댓글로 남겨주세요 :)
계정을 만드시고 그 다음에는 계정에 권한(IAM)을 부여해야 합니다. 클라우드에 익숙하지 않으면 이 개념이 어색할 수 있는데요, 쉽게 접근하면 ‘내 계정에 personalize 접근을 허용한다’라는 권한을 부여하는 것입니다. 또한 클라우드에는 스토리지가 있죠? personalize는 AWS의 스토리지인 S3를 통해 데이터를 받아옵니다. 따라서 위 과정에서 S3에 대한 접근 권한도 부여하게 됩니다. 자세한 방법은 2번 reference를 참고해주세요. (이 부분이 진행되지 않으면 이후 진행이 불가능합니다.)
Personalize를 구축하는 방법은 크게 3가지가 있습니다.
-
AWS console
-
AWS Python SDK
-
AWS CLI (Command Line Interface)
1번은 웹 상에서 AWS 콘솔을 통해 진행하며 가장 단순하고 하기 쉽다는 장점이 있습니다. 2번은 AWS CLI를 통해 작업하는 것, 3번은 AWS의 python API를 통해 Python 환경으로 작업하는 방법입니다.
단순한 테스트가 아닌 실제 서비스를 위해서는 스케쥴러, API Gateway 등 연동 부분도 고려해야 하므로 이 때는 2,3번으로 작업을 권장드리며, 지금은 1번 방법을 통한 구축 방법을 알아보겠습니다. 구축 순서는 다음과 같습니다. AWS 문서에 상세히 나와있어서 중요한 부분 위주로만 설명드리겠습니다.
S3에 데이터 적재
위에 말씀드린 것과 같이 Personalize는 S3를 통해 데이터를 적재해야 합니다. 상세 과정은 다음과 같습니다.
- 버킷 생성
- S3에 데이터를 저장하기 위해서는 버킷이라는 것을 생성해야 합니다. 버킷은 디렉토리 개념이며 버킷 이름은 유일한 이름을 가집니다.
- AWS 콘솔에서 S3에 들어가 버킷을 생성합니다.
- 버킷 권한 부여
- Personalize가 S3에서 데이터를 접근하려면 권한이 필요합니다.
- AWS Document에 나온대로 (
Amazon S3 버킷에 업로드참고)
- 데이터 적재
- Personalize가 처리할 수 있는 형태로 csv파일을 생성합니다.
- Interaction.csv(필수), item.csv(선택), user.csv(선택)을 S3에 업로드합니다. (자세한 데이터의 형태는 아래에서 다루겠습니다.)
데이터 로드 및 스키마 설정
S3에 데이터를 적재 후, 콘솔 상에서 데이터 로드 및 데이터에 대해 정의해주는 파트입니다.
- Personalize 추천 엔진의 데이터 형태
- Personalize를 사용하기 위해선 Interaction.csv, user.csv, user.csv가 필요합니다. Interaction은 반드시 필요한 필수 데이터이며, 나머지 2개는 선택사항입니다.
- Interaction.csv
- User가 item과 상호작용한 데이터입니다. 필수 항목은
USER ID,ITEM ID,TIMESTAMP입니다. - 영화 추천의 경우에는 user가 item을 본 시간이며, 상품 추천의 경우에는 user가 item을 구매 or 클릭한 시간이라고 생각하시면 됩니다.
- TIMESTAMP는 유닉스 시간을 사용합니다.
- 이 3가지 외에 칼럼 추가도 가능합니다.
ex)영화 추천 USER ID | ITEM ID | TIMESTAMP 김부장 라라랜드 1596161659 최대리 해리포터 1596166082 김부장 존윅 1596171438
- User가 item과 상호작용한 데이터입니다. 필수 항목은
- User.csv
- 유저의 메타(정보)에 관한 데이터입니다.
- 나이, 성별 등 유저의 고유 정보에 해당합니다.
ex)영화 추천 USER ID | SEX | AGE ... 김부장 남 43 최대리 여 32
- Item.csv
- 아이템의 메타(정보)에 관한 데이터입니다.
- 가격, 장르 등 아이템의 고유 정보에 해당합니다.
ex)영화 추천 ITEM ID | GENRE | ACTOR | PRICE ... 해리포터 | 판타지 | 래드클리프 | 0 신과함께 | 드라마 | 하정우 | 1,000
- Dataset groups 생성
- Dataset groups는 프로젝트 단위의 개념입니다. 콘솔의
Create dataset Group을 통해 생성합니다. - Personalize에 데이터를 업로드합니다.
import를 통해 데이터를 불러오겠습니다. - 먼저 이름 지정 및 스키마 설정을 합니다.
- 스키마(
Schema details)는 업로드한 데이터의 칼럼을 지정해주는 작업입니다. 이를 통해 칼럼명과 데이터 type을 정의합니다. (스키마는 쉽게 말해 personalize에게 “나 이런 형태의 데이터를 사용할 거야”라고 알려주는 작업입니다.) - 앞서 만든 3개의 csv파일은 생성되어 S3에 저장되어있습니다. Data location에 해당 파일의 경로를 지정하여 Personalize에서 불러올 수 있도록 설정합니다.
- Interaction만 import하여도 학습 진행이 가능합니다. User와 Item 데이터를 사용하려면 각 데이터를 위의 과정 동일하게 import 합니다.
- 만약 데이터가 추가되어 새로 업로드하고 싶다면,
Create dataset import job를 통해 재업로드합니다.
- Dataset groups는 프로젝트 단위의 개념입니다. 콘솔의
솔루션 생성
Interaction 데이터를 올바르게 업로드했다면 Create solution이 활성화됩니다.
Personalize에서 제공하는 레시피를 통해 추천 엔진을 구축할 수 있습니다. (personalize에서는 알고리즘을 레시피라 부릅니다.)
제공하는 레시피는 아래와 같고 추천의 목적에 맞게 선택하시면 됩니다.
- Personalize의 레시피 (20.12.12 기준)
aws-sims: CF기반의 알고리즘으로 주어진 아이템과 유사한 아이템을 추천 (Input:Item)aws-popularity-count: 인기도 모델로 데이터 세트에서 가장 인기 있는 항목을 추천, 모든 사용자에게 동일한 리스트 반환 (Input:User)aws-hrnn: Personalize의 대표 알고리즘인 Session 기반의 HRNN 알고리즘 (Input:User)aws-user-personalization: 2020년 말에 나온 레시피로 HRNN 및 기타 추천 알고리즘을 앙상블 형태로 제공? (제 추측 입니다…) (Input:User)aws-personalize ranking: 다른 레시피를 통한 추천 리스트 내에서 순위를 재설정하는 역할을 합니다. 추천 알고리즘의Ranking부분입니다.
머신러닝(딥러닝)을 학습할 때는 하이퍼파라미터를 설정해야 합니다. Personalize에는 일부 알고리즘에서 HPO (hyperparameter optimization)을 지원합니다.
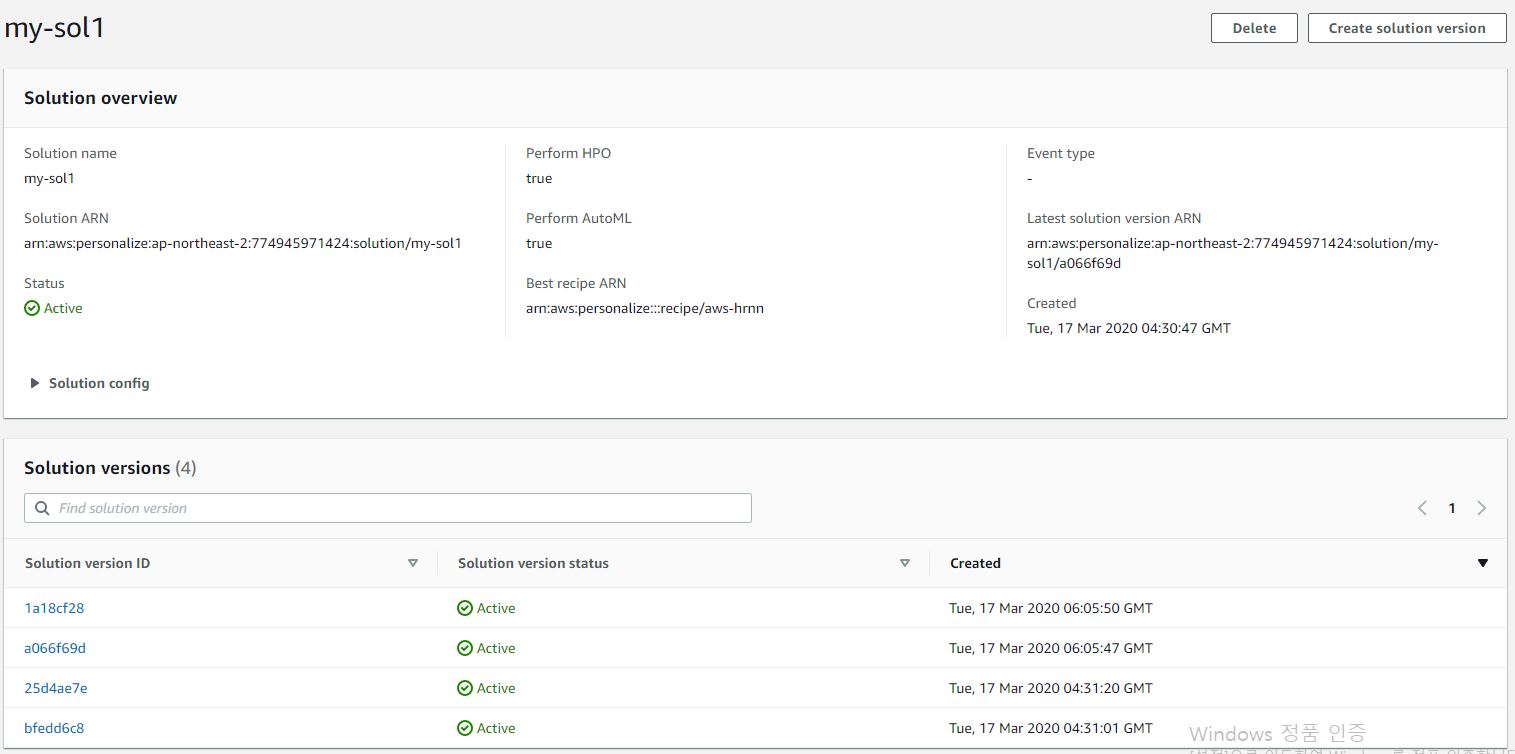
하이퍼파라미터 설정 후 솔루션을 생성하면 solution version이 생성됩니다. 재학습을 하고 싶다면 해당 버튼을 통해 재학습을 할 수 있습니다.
또한, 데이터를 추가 후 재학습을 원할 때도 해당 기능을 통해 재학습을 할 수 있습니다. 학습이 완료되면 아래의 solution versions와 같이 학습된 결과를 확인할 수 있습니다.
모델이 생성되었으면 모델의 성능을 알아봐야겠죠?
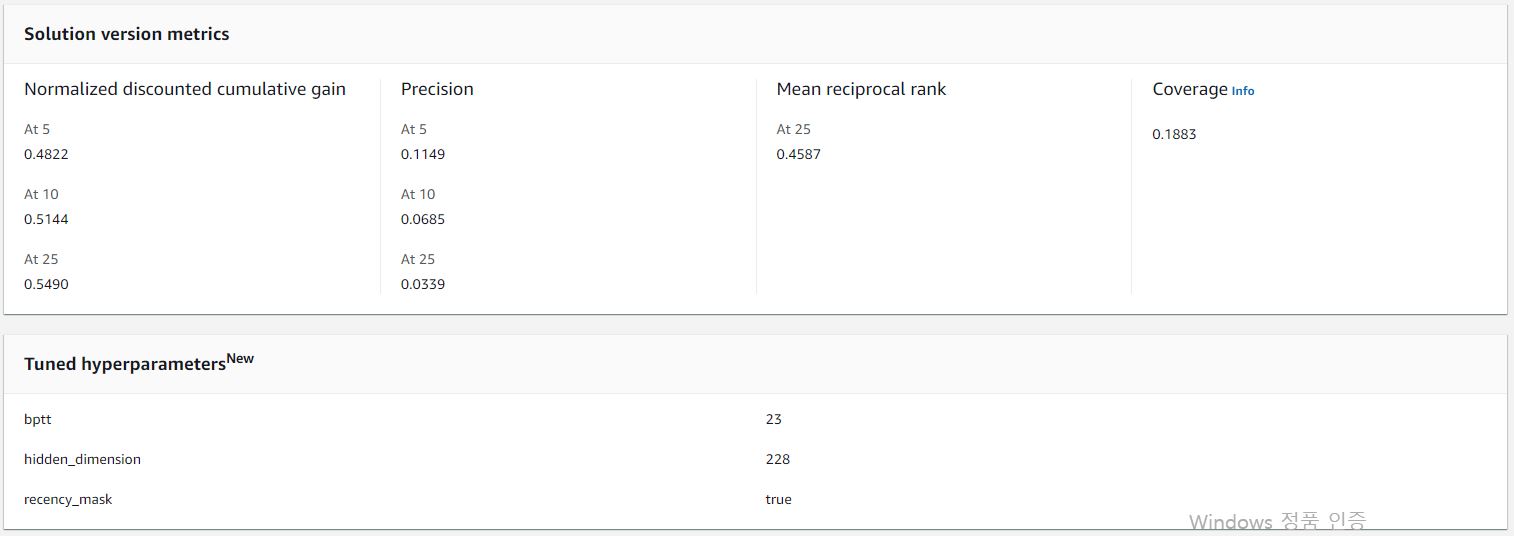
AWS Personalize는 솔루션 생성 시 오프라인 지표인 NDCG, Precision, MRR, Coverage에 대한 값을 제공합니다.
- 모델 성능 지표
Normalized discounted cumulative gain: 랭킹을 점수화한 지표로 순위가 높을수록 값이 큼Precision: 반환된 추천 리스트 중 유저가 관심있는 아이템 수(구매하거나 시청하거나)Mean reciprocal rank: 추천 리스트 중 첫번째로 유저가 관심 있어 하는 아이템 랭킹의 역순위 평균Coverage: 전체 아이템 중 추천 되는 아이템의 비율
아래 그림에서는 콘솔에서 보여지는 추천 성능 지표를 확인할 수 있습며, 지표 아래에는 HPO로 설정된 하이퍼파라미터를 볼 수 있습니다.
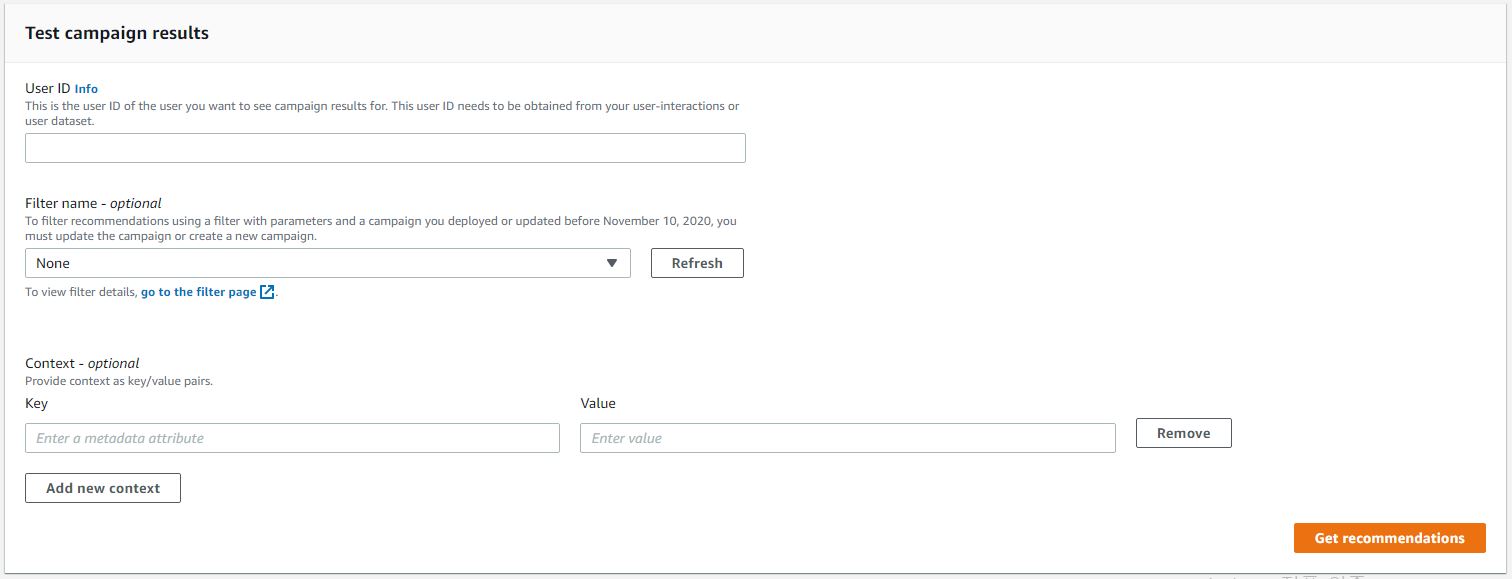
Campaigns 생성
Campaigns는 생성된 솔루션을 기반으로 추천 리스트를 API 형태로 제공하며, 솔루션에 사용한 레시피에 따라 다른 형태의 값을 API의 Input으로 받습니다.
SIMS 레시피 기반 campaign의 경우에는 ITEM ID를 입력값으로 받아 해당 ITEM과 관련 깊은 ITEM을 반환해 주며, 타 레시피의 campaign은 USER ID를 입력으로 받아 해당 유저가 선호할만한 ITEM 리스트를 반환해 줍니다.
아래의 그림은 HRNN을 사용한 솔루션의 campaign입니다.
기타 기능
Personalize에는 기타 유용한 기능이 존재합니다.
- AWS Personalize Filter
- 필터는 말 그대로 필터링을 해주는 역할을 하며, SQL 기반의 표현식으로 반환되는 추천 리스트를 제어할 수 있습니다.
- 예를 들어, 공포 장르의 영화를 추천 리스트에서 제거하고 싶을 때 ITEM.csv의 GENRE가 “공포”일 경우 제외한다는 표현식을 사용하여 해당 기능을 적용할 수 있습니다.
- AWS Personalize Event trackers
- Python SDK 등 방법으로 데이터를 수집할 수 있으며 실시간 추천을 위한 실시간 수집기 역할을 합니다.
- 학습 때는 사용되지 않으며 campaign에서 추천 리스트를 반환할 때 (Inference 과정) 수집된 데이터를 반영하여 추천 리스트를 생성합니다.
☝ Reference
- https://docs.aws.amazon.com/personalize/latest/dg/what-is-personalize.html
- https://docs.aws.amazon.com/personalize/latest/dg/aws-personalize-set-up-permissions.html
Leave a comment