개인화 포스터 추천을 위한 포스터 분류 모델
이번 포스트에서는 영화 포스터 장르 분류 모델을 구축해보겠습니다.
미디어 쪽에서의 추천하면 일반적으로 콘텐츠 즉, 영화나 TV방송과 같은 아이템 항목에 대한 추천을 떠올리기 마련입니다. 그렇다면 추천된 영화는 UI상 포스터를 통해 사용자에게 처음 보여지겠죠? 사용자가 맨 처음 콘텐츠를 접하는 매개체는 포스터이며, 따라서 포스터는 첫인상 관점에서 중요한 포인트입니다. 이 때문에 넷플릭스에서는 이미 Artwork라는 개인화 포스터 서비스를 제공하고 있습니다.
넷플릭스 기술 블로그에서 언급되는 대표적인 개인화 포스터 시나리오는 선호 장르 기반의 포스터 추천입니다. 선호하는 장르 느낌을 풍기는 포스터를 추천하거나 선호하는 장르와 매칭되는(특정 장르에 자주 출연한) 배우가 등장한 포스터를 추천하는 방법을 예로 들고 있습니다. 또한 선호하는 배우 기반의 포스터 추천도 가능합니다.
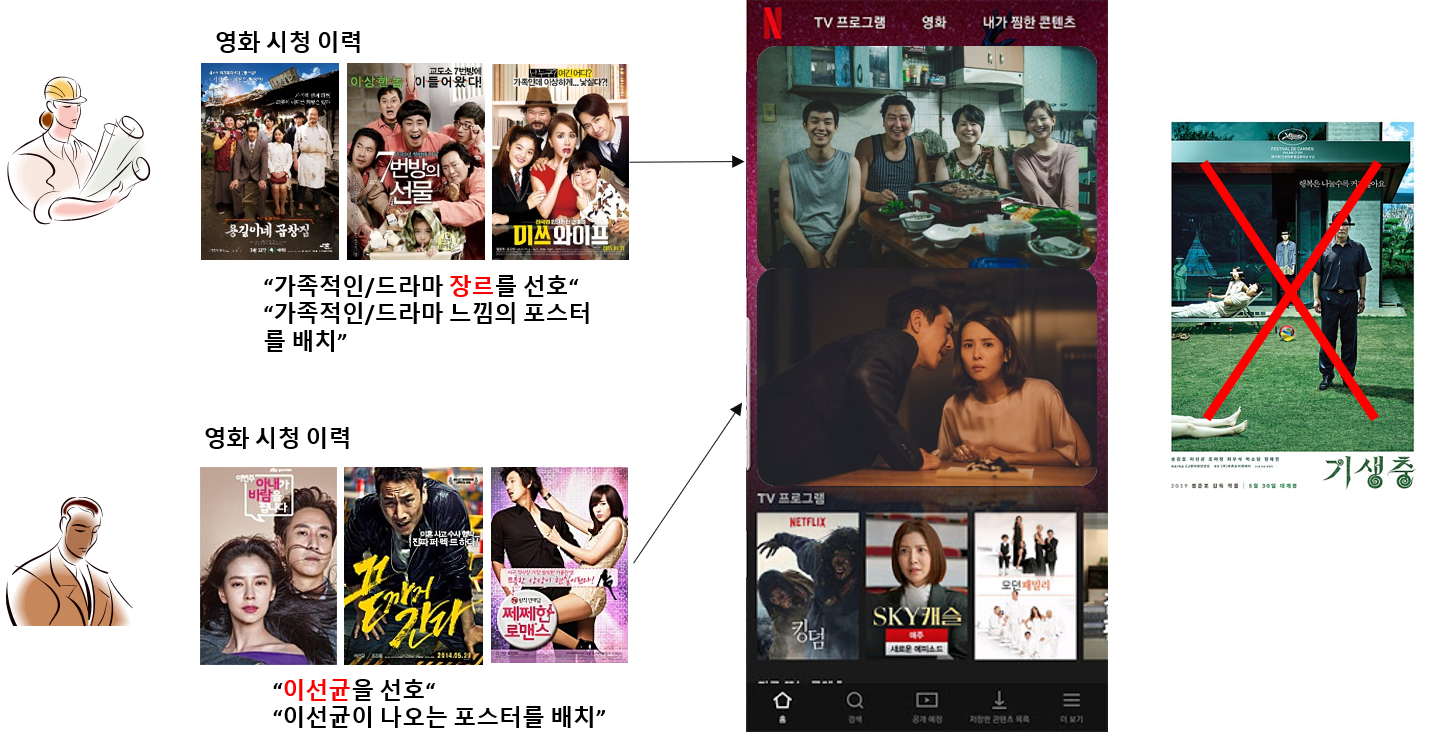
이를 그림으로 살펴보겠습니다. 가족적인/드라마 장르를 선호하는 A에게 기생충을 추천한다고 할 때, 기존 포스터가 아닌 가족적인 느낌을 주는 포스터를 보여줌으로써 콘텐츠의 첫인상을 높이는 역할을 할 수 있으며, 이선균이 등장하는 영화를 많이 본 B에게는 이선균이 등장하는 포스터를 추천함으로써 사용자의 관심을 끌도록 유도합니다. 사실 대표 포스터는 작품성을 가장 잘 드러내며 많은 정보를 내포하기 마련이지만 개인화 포스터가 기여할 수 있는 부분은 많다고 생각합니다. 가령, 종교 문제 등 민감한 부분이 내포된 포스터를 대체하는 방식 등으로 말이죠.
이런 시나리오 중 선호하는 장르와 유사한 느낌을 풍기는 포스터를 추천해주려면 장르가 태깅된 다양한 포스터가 필요합니다. 하지만 다양한 포스터에 대해 일일이 장르를 태깅하는 것은 비용적으로 비효율적이기 때문에 자동으로 포스터의 장르를 구분할 수 있는 포스터 장르 분류 모델을 만들어봤습니다.
여기서는 중요한 가정이 하나 들어갑니다. “영화의 메인 포스터는 영화의 장르를 내포한다”입니다. 일반적으로 장르라는 것은 영화에 대한 장르지 포스터에 대한 장르가 아닙니다. 따라서 위 가정이 없다면 데이터 label 관점에서 신뢰성의 이슈가 생기게 됩니다. 현재 수준으로는 모든 포스터에 대해서 label된 데이터도 없고, 포스터 자체가 하나의 장르로 지정되는 것에도 문제가 존재하기 때문에 영화 장르 = 포스터 장르라는 가정을 기반으로 작업들을 진행했습니다.
최종적으로는 영화의 대표 포스터를 통해 포스터 장르 분류 모델을 만들었습니다. 개발 순서는 네이버 포스터 크롤링, 전처리, 분류 모델(CNN), 후처리 순으로 진행했고 앞으로 하나씩 살펴보겠습니다.
1.크롤링
분류 모델 생성을 위해 영화 포스터와 영화의 장르(=포스터 장르)를 크롤링했습니다. 해당 블로그에서 크롤링의 A-Z까지 다루는 것은 낭비인 것 같고..(다른 곳에 잘 정리된 글이 많습니다.) 저는 크롤링할 때 유의할 점 위주로 다루겠습니다. 먼저 체크해야할 점은 원하는 데이터 수준을 만족하는 페이지를 찾아야하는 것입니다. 저의 경우는 최대한 많은 영화(포스터)가 필요했고, 크롤링 반복을 통해 최대한 많은 영화를 추출할 수 있는 페이지를 선정해야했습니다. 네이버에서 제공하는 영화 정보는 두가지 페이지가 제공합니다.
- https://movie.naver.com/
- https://serieson.naver.com/movie/home.nhn
1번의 경우는 랭킹 탭에서 다수의 영화를 제공하지만 개수가 원하는 수준이 아니었고, 디렉토리에서는 옛날 영화가 너무 많아 원하는 데이터 수준을 만족하지 못했습니다.
2번의 경우는 최신영화 부분에 ‘입고순’을 하면 만개 이상의 최신 순 영화 정보를 얻을 수 있었습니다. 그래서 크롤링 대상 페이지를 2번으로 설정하고, 필요한 부분을 소스 보기의 HTML 태그 부분을 따와 크롤링을 진행했습니다. 여기서 19세 영화의 상세페이지를 누르면 로그인이 필요한데 이 때문에 단순히 반복 크롤링을 설정하면 도중에 멈추게 됩니다. 따라서 이를 방지하기 위해 예외 처리 작업을 해줘야합니다. 저는 연령 제한 영화는 대상에서 제외했기 때문에 해당 영화는 예외처리하여 크롤링을 진행했습니다.
그 다음으로는 추출하려는 정보에 해당하는 태그를 “페이지 소스보기”에서 찾아 크롤링하는 것입니다. 이 부분이 조금만 익숙해지면 HTML 문법을 몰라도 원하는 정보를 어려움없이 추출할 수 있습니다.
전체 크롤링 코드는 아래와 같습니다.
# 참조 https://www.coalastudy.com/feed/1516
import requests
from bs4 import BeautifulSoup
import openpyxl
from urllib.request import Request, urlopen
from urllib.request import urlretrieve
import ssl
import re
import pandas as pd
wb = openpyxl.Workbook()
sheet = wb.active
sheet.append(["영화제목", "포스터URL", "장르"])
pageNum = 800
count = 1
titles = []
genres = []
urls = []
while count < pageNum + 1:
target_url = "https://serieson.naver.com/movie/recentList.nhn?orderType=rls_ymd&sortingType=&tagCode=&page="+str(count)
res = urlopen(target_url)
bs = BeautifulSoup(res, 'html.parser')
tags = bs.select('div.lst_thum_wrap li a')
#tags_img = bs.select('div.lst_thum_wrap li a')
for tag in tags:
url = 'https://serieson.naver.com' + tag['href']
res1 = urlopen(url)
bs1 = BeautifulSoup(res1, 'html.parser')
soup = bs1.find("span", {"class":"pic_area"})
if soup:
imgUrl = soup.find("img")["src"][:-8] + 'm665_443_2'
title = soup.find("img")['alt']
genr = []
genre_soup = bs1.select('li.info_lst > ul > li:nth-child(3) > a')
for genre in genre_soup:
genr.append(genre.text)
titles.append(title)
urls.append(imgUrl)
genres.append(genr)
else:
pass
print("completed page :", count)
count += 1
my_dict = {"title":titles, "urls":urls, "genres":genres}
my_dataFrame = pd.DataFrame(my_dict)
saveurl ="movie_0804.csv"
my_dataFrame.to_csv(saveurl, index=False, encoding='utf-8-sig')
2.모델 생성
test
고찰…
개인화 포스터는 개념적으로는 OK지만 필요한 것도 많고 검증의 과정이 까다롭다고 생각합니다.
-
포스터 Pool이 필요합니다. 다양한 사람의 취향을 반영하는 포스터를 추천하기 위해선 그에 맞게 콘텐츠 별 포스터 Pool이 필요합니다. (돈…) 일반적으로 포스터는 가로형, 세로형으로 구분되며 제작사에서 다양한 포스터를 제공하는 케이스도 있습니다. 혹여 굳이 직접 공수를 한다면 스틸컷과 같이 직접 장면을 따와 사용하는 방법도 고려할 수 있어 보입니다. 단, 이는 저작권 문제와도 연관되므로 검토가 필요합니다.
-
기존 포스터가 아닌 다른 포스터를 보여주는 것은 사용자에게 오해를 일으킬 수 있습니다. 가령, 조연이 메인인 포스터를 추천해서 반감을 가진다거나, 공포 영화를 극도로 싫어하는데 공포 느낌이 적은 포스터를 추천하여 반감을 가지는 경우가 있을 거 같습니다. 이런 부분을 보면 무조건 적용보다는 케이스에 따라 적용하는 것이 옳아보입니다.
-
장르 기반 포스터 추천 이외에도 개인화 포스터는 적용할 수 있는 포인트가 많은 분야입니다. 위에 언급한 민감한 부분에 대한 정보 제거라던가 배우 기반 등 적용 포인트는 많다고 생각합니다.
-
투자 대비 아웃풋이… 대작을 구매하여 콘텐츠 수급을 하는 것이 포스터를 구매하는 것보다 사업적인 관점에서 더 가치있는 일이 될 수 있습니다. A/B 테스트를 통한 제대로된 검증이 필요합니다.
Leave a comment