추천 알고리즘 : CF
이번 포스트에서는 가장 대표적인 추천 알고리즘인 CF에 대해 알아보겠습니다.
Collaborative Filtering(CF)은 협업 필터링으로 불리는데요, 그 뜻과 같이 다른 사용자와의 협업에 기반한 알고리즘입니다.
아이템 고유 정보를 기반으로 하는 content based filtering(CBF)와는 다르게 CF 알고리즘은
사용자와 아이템의 선호도에 기반하여 비슷한 선호도를 가진 user를 식별하는 알고리즘입니다. 이 말은 즉, 나와 선호도가 유사한 사람의 사례를 통한 추천이라는 말입니다.
저는 계산 방법에 따라 CF 알고리즘을 다음과 같이 3가지로 분류하고 싶습니다.
User/item based CFMF, FMDeep learning CF
1번은 유사도 기반의 단순한 CF 알고리즘이고, 2번은 행렬 연산에 기반한(+선형대수) CF 알고리즘입니다. 3번은 다른 두가지에 비해 늦게 화두가 된 딥러닝 기반의 CF 알고리즘입니다.
모든 CF 알고리즘의 목표는 “사용자가 평가하지 않은 (or 선호도를 알 수 없는 or 접하지 않은) 아이템에 대한 평가(or 선호도)를 예측하는 것” 입니다. 추천은 이렇게 구한 선호도를 기반으로 TOP N개 제공하는 것입니다. 이를 위 분류에 대입하면 1번은 유사도 기반으로 평가 점수를 구하는 것이고, 2번은 행렬 연산을 통해 평가하지 않은 선호도를 예측하는 것입니다. 마지막으로 3번은 딥러닝 모델을 통해 선호도를 예측하는 것입니다.
이렇게 나눈 것이 논란이 될 수 있는데, CF의 범위를 상호작용 데이터를 사용하는 알고리즘이라고 가정하면 위와 같이 나눌 수 있고, CF를 딥러닝과 별개의 것으로 구분하면 딥러닝을 제외한 1,2번이 CF라고 생각할 수 있습니다. (저는 CF라는 것은 상호작용 데이터를 사용한 알고리즘이라 생각해서 CF와 딥러닝을 따로 구분짓지 않았습니다. 그리고 딥러닝 기반의 추천 알고리즘은 거의 모두 상호 작용 데이터가 포함됩니다… 분류 체계는 정의하기 나름인 거 같습니다!)
이제 CF알고리즘에 대해 하나씩 살펴보겠습니다.
User/item based CF
예전부터 현재까지 두루 사용되고 추천에서 가장 기본이 되는 알고리즘이며, Memory-based algorithm 이라고도 부릅니다.
이 방법을 사용하기 위해선 User-item matrix를 만들어야 합니다. 이 행렬은 행과 열이 각각 item, user가 되며 matrix size는 (item 수, user 수)가 됩니다.
이 행렬에서 user-based CF 는 user 유사도 기반으로 평가가 유사한 user를 찾은 후 접하지 않은 item의 선호도를 추론하는 것이며, item-based CF 는 item 유사도 기반으로 평가가 유사한 item을 찾은 후 item 대한 user의 선호도를 구하는 것입니다.
그림으로 예시를 보시겠습니다.
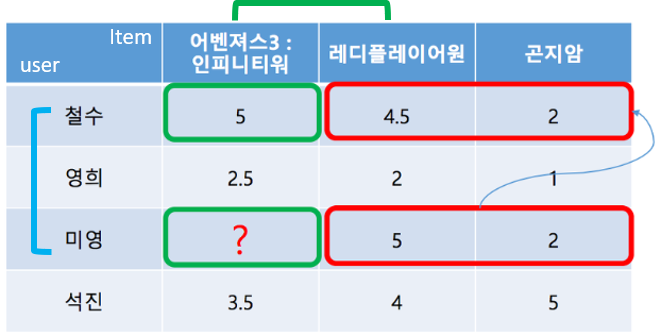
위 상황은 사용자에게 영화를 추천하는 시나리오입니다. 사용자는 철수, 영희, 미영, 석진이고 아이템(영화)은 어벤져스3, 레디플레이어원, 곤지암일 때 각 사용자가 위 표와 같이 영화를 평가했다고 가정하겠습니다. 이 때 어벤져스를 보지 않은 미영이에게 어벤져스를 추천할 것인지를 결정해보겠습니다. 표에서도 볼 수 있듯이 현재 미영이는 어벤져스를 시청하지 않아 해당 영화에 대한 선호도를 알 수 없습니다. 물음표로 표시된 선호도를 추정하여 선호도가 높으면 어벤져스를 추천해주고, 선호도가 높지 않아 해당 영화를 추천해주지 않는 것이 추천 시나리오입니다.
User based CF는 미영이와 취향이 비슷한 사람 을 찾는 것입니다. 직관적으로 보면 미영이가 평가한 다른 영화인 레디플레이어원과 곤지암을 통해 미영 이와 유사한 평가를 한 사람은 철수 라는 것을 알 수 있고, 이는 미영이와 철수의 취향이 비슷하다는 것을 의미합니다. 이를 통해 미영이는 어벤져스를 선호할 것으로 보이며 계산하고자하는 ?는 4~5점 정도라고 추측할 수 있는데 이 평가 점수의 실제 계산은 유사도 측정을 통해 가능합니다.
유사도 평가는 코사인 유사도, 자카드 유사도 등의 방법이 있는데 코사인 유사도를 대표적으로 많이 사용합니다. 이 유사도 공식은 벡터의 유사도를 판별하는데 유저 간의 유사도를 판별하기 위해 공통 평가 항목에 대해 벡터화를 시킨 후 코사인 유사도 공식에 대입하여 사용자 간의 유사도를 구할 수 있습니다. 이를 모든 사용자에 적용하여 M by M의(M:사용자 수) 사용자 유사도 행렬을 구하고, 유사도와 다른 사람이 평가한 점수의 weighted sum을 통해 해당 유저가 평가하지 않은 항목의 평가 점수를 구할 수 있습니다. 계산 방법으로는 가장 유사도가 큰 사람을 통해 계산, 유사도가 큰 상위 n명의 유사도를 통해 계산, 전체 사람의 유사도를 통해 계산 등의 방법을 통해 평가하지 않은 항목에 대한 값을 구할 수 있습니다.
Item based CF는 아이템 유사도를 기반으로 위에 봤던 방법과 유사합니다. 즉, 미영이의 어벤져스 평가 점수를 예측하기 위해 어벤져스와 비슷한 영화 를 item 내에서 찾는 것입니다. 이를 위해 이번에는 N by N의(N:아이템 수) 아이템 유사도를 앞서 살펴본 유사도 평가를 통해 구하고, weighted sum을 통해 평가하지 않은 항목에 대한 값을 계산할 수 있습니다. 이때 User based CF와 같이 Item based CF도 가장 유사도가 큰 아이템을 통해 계산, 유사도 큰 상위 n개의 유사도를 통해 계산, 전체 아이템의 유사도를 통해 계산 등의 방법을 통해 평가하지 않은 항목에 대한 값을 구할 수 있습니다.
조건
이 방법을 사용하기 위해서는 두 가지 조건이 필요합니다.
1. 유저가 아이템을 평가한 점수가 필요하다는 것
2. 평가 점수가 어느 정도 있는 상태여야 한다는 것
첫번째 조건에 대해 살펴보겠습니다. 유사도 계산을 위해서는 평가 점수가 필요한데, 이렇게 유저가 아이템에 대해 선호도를 평가한 데이터로 explicit feedback(rating) 이라고 하며 클릭(시청) 여부, 접속 시간 등 간접적으로 선호도를 내포한 데이터를 implicit feedback 이라 합니다. Explicit/implicit feedback은 내용이 꽤 되어 이후에 다시 살펴보도록 하겠습니다. 다시 돌아와서 위 방법을 사용하기 위해서는 explicit feedback이 필요한데, 실제 상용 서비스에서는 평가 데이터를 얻기 힘들 뿐만 아니라 얻더라도 그 양이 전체 아이템에 비해 매우 부족한 경우가 많습니다. 그래서 implicit data를 explicit data로 추정하는 방법들이 많이 나왔고, 이를 평가 점수로 사용하는 사례도 많이 존재합니다.
두번째 조건은 위에도 잠깐 언급했는데 평가 점수가 부족할 경우에는 계산에 대한 신뢰도가 떨어질 위험이 있습니다. 예를 들어, 특정 영화에 대한 평가를 100명의 사람 중에 2명만 했을 경우, 2명의 평가를 통해 유사도를 계산하는데 그렇데 된다면 정확도가 매우 부정확할 가능성이 크게 됩니다. 그래서 실제 추천 시스템을 구축 시에 N명 이상일 경우에 대해서만 유사도를 계산하는 처리 과정을 통해 이런 문제를 해결하곤 합니다.
추천 서비스 관점에서
-
실제 추천 서비스에서는
Item based CF가 주로 사용됩니다. 그 이유는 user 유사도 보다 item 유사도를 구하는 것이 계산량이 적으며,(일반적으로 아이템 개수 < 유저 수) 성능면에서도 item based CF가 뛰어나다고 알려져 있습니다. -
또 고려할 점은 유사도 계산입니다. 일반적으로 User-item matrix는 빈 값이 많고 큰
sparse matrix입니다. 예를 들어 유저 수가 10만명, 아이템 수가 2만개일 경우에 user 유사도 행렬은 10만 by 10만이 되는데 이럴 경우 일반적으로 사용하는 sklearn 라이브러리를 통해서는 연산량 초과 에러가 뜰 수 있습니다. 이 경우에는 행렬에서 채워진 항목만을 저장하여 연산하는 CSR, COO 방식을 통해 계산할 수 있습니다. -
평가 성향에 대한 반영이 필요합니다. A라는 사람은 보통 평점을 4점을 주는데 a라는 영화에 대해 3점을 줬다면 그 영화를 덜 선호한다고 볼 수 있습니다. 반면 B라는 사람은 평균 2점의 평점을 주는데 a라는 영화에 3점을 줬다면 B는 해당 영화를 선호한다고 볼 수 있습니다. 이처럼 A,B가 점수는 같지만 점수는 상대적인 것이기 때문에 평균을 빼는 연산을 넣는 등 정규화 과정을 통해 추천 시스템의 정확도를 올릴 수 있습니다.
정리
장점
- 간단하게 구현 가능
- 직관적
- 기본적인 성능 보장
단점
- Cold start 문제
- 행렬이 너무 클 경우 처리 불가능할 수 있음
- Interaction(평가) data가 적을 경우 정확도 이슈
Leave a comment